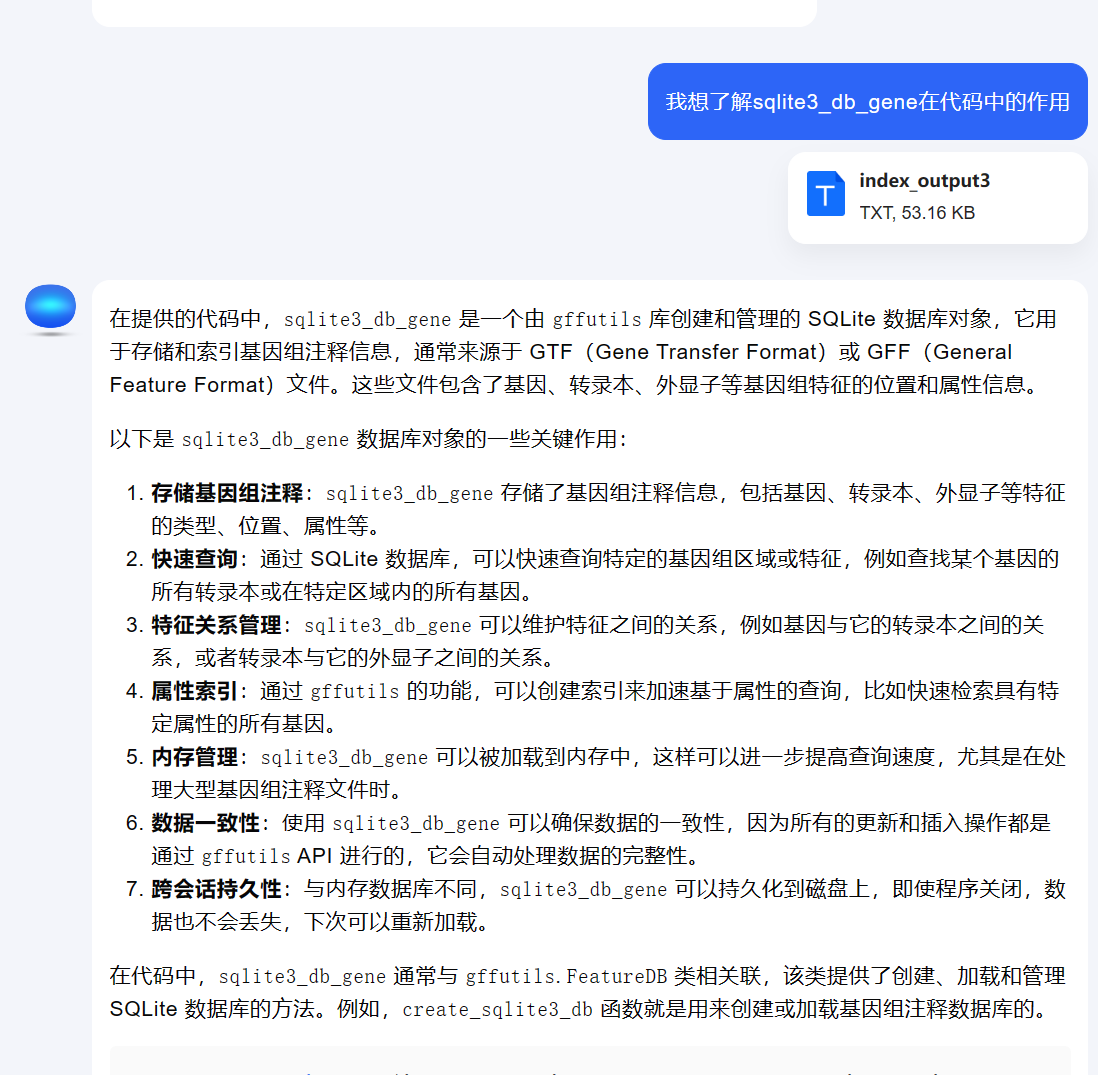
思路: https://resources.aertslab.org/cistarget/ 提供了全面的非冗余的motif数据库,以及人类、动物和昆虫的TF与motif对应表格,因此,如果研究动物,则基于同源序列相似性,将基因编号与人类基因对应,研究昆虫,则与果蝇对应。数据库中,Mouse和Chicken就是基于同源基因跟人类基因对应得到。
首先,配置create_cisTarget_databases环境
# Clone git repo.git clone https://github.com/aertslab/create_cisTarget_databases~~~~cd create_cisTarget_databases# Display to which value ${create_cistarget_databases_dir} variable should be set.echo "create_cistarget_databases_dir='""${PWD}""'"# Create conda environment.conda create -n create_cistarget_databases \ 'python=3.10' \ 'numpy=1.21' \ 'pandas>=1.4.1' \ 'pyarrow>=7.0.0' \ 'numba>=0.55.1' \ 'python-flatbuffers' # Activate conda environment.conda activate create_cistarget_databasescd "${CONDA_PREFIX}/bin"# Download precompiled Cluster-Buster binary.wget https://resources.aertslab.org/cistarget/programs/cbust# Download liftOver.wget http://hgdownload.soe.ucsc.edu/admin/exe/linux.x86_64/liftOver# Download bigWigAverageOverBed.wget http://hgdownload.soe.ucsc.edu/admin/exe/linux.x86_64/bigWigAverageOverBed# Make downloaded binaries executable.chmod a+x cbust liftOver bigWigAverageOverBed# 安装一些库pip install pandas==1.3.5 pyranges pyfaidx
下一步,是启动环境,并配置好create_cistarget_databases_dir的路径,例如我是家目录下,那么路径应该写成
# Activate conda environment.conda activate create_cistarget_databases# Set ${create_cistarget_databases_dir} variable to path where the repo was cloned to.create_cistarget_databases_dir=$HOME/create_cisTarget_databases
我们以Pig为例,创建文件夹,并从ENSEMBLE上下载相关的文件
mkdir -p GRN_DBcd GRN_DB# 下载基因组序列和GTF文件wget https://ftp.ensembl.org/pub/release-112/fasta/sus_scrofa/dna/Sus_scrofa.Sscrofa11.1.dna.toplevel.fa.gzwget https://ftp.ensembl.org/pub/release-112/gtf/sus_scrofa/Sus_scrofa.Sscrofa11.1.112.gtf.gzpigz -d Sus_scrofa.Sscrofa11.1.112.gtf.gz
此外,下载CISTARGET提供的现成的motif数据。
wget https://resources.aertslab.org/cistarget/motif_collections/v10nr_clust_public/v10nr_clust_public.zipunzip v10nr_clust_public.zip
从ENSEMBLE上下载的GTF文件中可能包含gene_name这一记录,一般对应的是人类的同源基因,因而可以得到当前物种的基因与人类基因的对应关系。我编写了一个脚本用于提取,
import redef parse_gtf(gtf_file): gene_info = {} with open(gtf_file, 'r') as file: for line in file: if line.startswith('#'): continue # Skip header lines fields = line.strip().split('\t') if fields[2] == 'gene': attributes = fields[8] gene_id_match = re.search('gene_id "([^"]+)"', attributes) gene_name_match = re.search('gene_name "([^"]+)"', attributes) if gene_id_match: gene_id = gene_id_match.group(1) gene_name = gene_name_match.group(1) if gene_name_match else gene_id gene_info[gene_id] = gene_name return gene_infodef save_gene_info(gene_info, output_file): with open(output_file, 'w') as file: for gene_id, gene_name in gene_info.items(): file.write(f'{gene_id}\t{gene_name}\n')# Path to your GTF fileimport sysgtf_file_path = sys.argv[1]# Output file pathoutput_file_path = sys.argv[2]# Parse the GTF filegene_info = parse_gtf(gtf_file_path)# Save the gene info to a filesave_gene_info(gene_info, output_file_path)print("Gene ID to Gene Name mapping has been saved to", output_file_path)
将其保存到一个gene2symbol.py 文件中,并运行,得到gene2symbol.txt
python3 gene2symbol.py Sus_scrofa.Sscrofa11.1.112.gtf gene2symbol.txt
然后,基于gene2symbol.txt,对v10nr_clust_public/snapshots/motifs-v10-nr.hgnc-m0.00001-o0.0.tbl 进行过滤,只保留存在同源基因tbl
import pandas as pdimport sys# 路径可能需要根据你的文件系统进行调整motifs_file = sys.argv[1]gene2symbol_file = sys.argv[2] # 读取 gene2symbol 文件并建立基因名集合gene_names = set()with open(gene2symbol_file, 'r') as file: for line in file: parts = line.strip().split() if len(parts) > 1: # 确保行有两个以上的部分 gene_names.add(parts[1]) # 假设第二列是基因名# 读取 motifs 文件并直接输出符合条件的行with open(motifs_file, 'r') as file: headers = next(file).strip() # 读取头部行 print(headers) # 输出头部行 for line in file: if line.startswith('#'): print(line.strip()) else: parts = line.strip().split('\t') if len(parts) > 5 and parts[5] in gene_names: print(line.strip()) # 输出符合条件的行
存在一个名为filter_tbl.py的脚本中,然后运行
python3 filter_tbl.py gene2symbol.txt v10nr_clust_public/snapshots/motifs-v10-nr.hgnc-m0.00001-o0.0.tbl > motifs-v10-nr.Sus.tbl
然后,我们从 motifs-v10-nr.Sus.tbl提取出所有的motif,并过滤掉,不存在与singletons的motif
grep -v '^#' motifs-v10-nr.Sus.tbl|cut -f 1 |sort -u > motif_all.txtls v10nr_clust_public/singletons | cut -d '.' -f 1 > motif_nr.txtgrep -Ff motif_all.txt motif_nr.txt > motifs_sus.txt
此外,还需要基于基因组序列和注释文件,提取序列
from pyfaidx import Fastaimport pyranges as primport argparsedef read_fasta(filename): """Read a FASTA file using pyfaidx, which provides efficient access to sequences.""" return Fasta(filename) # This will index the file if not already indexeddef write_fasta(fasta_dict, output_filename): """Write a dictionary to a FASTA file.""" with open(output_filename, 'w') as file: for header, sequence in fasta_dict.items(): file.write(f">" + header + "\n") file.write(sequence + "\n")def extract_sequence(fasta, chrom, start, end): """Extract sequence from a FASTA file using pyfaidx.""" sequence = fasta[chrom][start:end].seq return sequencedef main(): parser = argparse.ArgumentParser(description="Extract sequences around gene start positions considering gene strand orientation.") parser.add_argument("genomic_fasta_filename", help="Genomic FASTA file.") parser.add_argument("gtf_filename", help="GTF file containing gene annotations.") parser.add_argument("output_fasta_filename", help="Output FASTA file for extracted sequences.") parser.add_argument("upstream_bp", type=int, help="Number of base pairs to extract upstream of each gene start considering strand.") parser.add_argument("downstream_bp", type=int, help="Number of base pairs to extract downstream of each gene start considering strand.") parser.add_argument("-n", "--name_field", default="gene_name", help="Field in GTF to use for naming sequences. If not found, an error will be raised.") args = parser.parse_args() # Load the FASTA file using pyfaidx fasta = read_fasta(args.genomic_fasta_filename) # Load GTF file using PyRanges gr = pr.read_gtf(args.gtf_filename) genes = gr[gr.Feature == "gene"] # Prepare the new FASTA entries new_fasta = {} for idx, row in genes.df.iterrows(): chrom, start, end, strand = row['Chromosome'], row['Start'], row['End'], row['Strand'] gene_name = row[args.name_field] if not isinstance(gene_name, str): continue if strand == '+': upstream_start = max(0, start - args.upstream_bp) downstream_end = start + args.downstream_bp else: upstream_start = end - args.downstream_bp downstream_end = end + args.upstream_bp # Ensure downstream end does not exceed chromosome length chrom_length = len(fasta[chrom]) downstream_end = min(downstream_end, chrom_length) # Extract and save the sequence extracted_sequence = extract_sequence(fasta, chrom, upstream_start, downstream_end) new_fasta[gene_name] = extracted_sequence # Write the new fasta file write_fasta(new_fasta, args.output_fasta_filename)if __name__ == "__main__": main()
提取以gene的起始的上游1kb,下游0bp, 用gene_name作为序列命名
python3 extract_fasta.py -n gene_name Sus_scrofa.Sscrofa11.1.dna.toplevel.fa Sus_scrofa.Sscrofa11.1.112.gtf gene_up1kb_down0kb.fasta 1000 0
最后运行create_cistarget_motif_databases进行构建
# FASTA file with sequences per region IDs / gene IDs.fasta_filename=gene_up1kb_down0kb.fasta# Directory with motifs in Cluster-Buster format.motifs_dir=v10nr_clust_public/singletons# File with motif IDs (base name of motif file in ${motifs_dir}).motifs_list_filename=motifs_sus.txt# cisTarget motif database output prefix.db_prefix=Sus_scrofa_up1kb_down0kbnbr_threads=24"${create_cistarget_databases_dir}/create_cistarget_motif_databases.py" \ -f "${fasta_filename}" \ -M "${motifs_dir}" \ -m "${motifs_list_filename}" \ -o "${db_prefix}" \ -t "${nbr_threads}"
最终,GRN所需要的文件如下
- tbl: motifs-v10-nr.Sus.tbl
- motif_name: motifs_sus.txt
- feather: 有三个, 按需使用
- Sus_scrofa_up1kb_down0kb.motifs_vs_regions.scores.feather
- Sus_scrofa_up1kb_down0kb.regions_vs_motifs.rankings.feather
- Sus_scrofa_up1kb_down0kb.regions_vs_motifs.scores.feather
]]>