高通量数据比对讲究的就是一个快和准,因此大部分软件都是用C语言实现。BWA是目前基因组序列比对最常用的工具,由于自我感觉已经入门C语言,为了提高自己的水平,因此开始从源码角度学习李恒大神开发的BWA工具。
使用 bwa index 建立索引后,会得到以下后缀的文件, .amb, .ann, .pac, .bwt, .sa. 我们通常也不在乎这些文件是什么,除非你像我一样,想搞懂bwa建立索引的具体过程。这次我们先来介绍.amb, .ann和.pac这三个文件是什么。
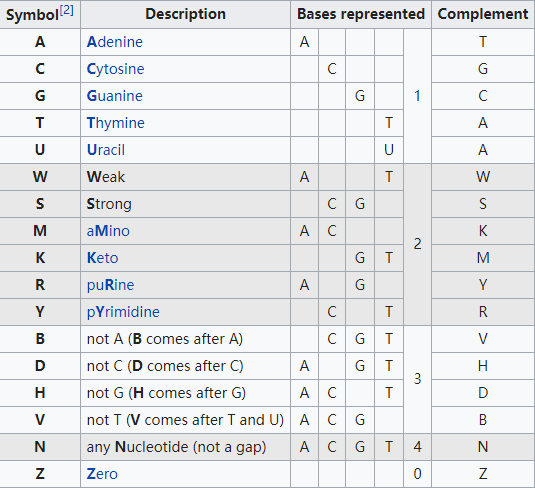
先说结论,amb是ambiguous的缩写,也就是模棱两可(兼并碱基)的意思,也就是除了ATCG/atcg以外的字符. amb和ann用来记录基因组中除了ATCG以外碱基的信息。而pac文件则是碱基信息高度压缩。
接下来的介绍,主要涉及到两个文件,bntseq.h和bntseq.c, 这里面的代码就是用于将fasta转成amb, ann和pac这三个文件。
在bntseq.h的开头,就定义了对应输出文件的三种数据结构, bntann1_t, bntamb1_t和bntseq_t
typedef struct {
int64_t offset; //染色体偏移量
int32_t len; //染色体长度
int32_t n_ambs; //多少个模糊碱基
uint32_t gi;
int32_t is_alt;
char *name, *anno; //染色体名名和注释
} bntann1_t;
typedef struct {
int64_t offset; //偏移量
int32_t len; //长度
char amb; //模式碱基的字符
} bntamb1_t;
typedef struct {
int64_t l_pac;
int32_t n_seqs; //基因组序列数
uint32_t seed; //随机数种子
bntann1_t *anns; // n_seqs elements
int32_t n_holes; //染色体有多少个空缺
bntamb1_t *ambs; // n_holes elements
FILE *fp_pac;
} bntseq_t;
前两种数据结构能够保存成文本,我们以拟南芥基因组为例。ann文件前几行如下,它记录每个染色体信息,以及里面amb数目
239335500 7 11 # bns->l_pac, bns->n_seqs, bns->seed)
0 Chr1 (null) # p->gi, p->name, p->anno
0 30427671 363 # p->offset, p->len, p->n_ambs
0 Chr2 (null)
30427671 19698289 58
...
amb文件前几行如下,它 记录确切的amb位置
239335500 7 563 # bns->l_pac, bns->n_seqs, bns->n_holes
12192623 1 Y # p->offset, p->len, p->amb
13201252 100 N # p->offset, p->len, p->amb
...
第三种数据结构,bntseq_t,则是用于打包将前两者的信息进行了整合,同时记录pac文件的文件指针地址。
对于pac文件,他通过哈希映射的方法(哈希函数如下),把一个比较大的位置映射到比较小的位置中,保证了最终序列文件大小低于原始文件。
#define _set_pac(pac, l, c) ((pac)[(l)>>2] |= (c)<<((~(l)&3)<<1))
#define _get_pac(pac, l) ((pac)[(l)>>2]>>((~(l)&3)<<1)&3)
总结一下,amb,ann,pac这三个文件主要是用于压缩原始的参考基因组序列,将碱基信息分为两部分,ATCG和其他兼并碱基的序列。amb记录兼并碱基的具体位置,ann记录参考基因组中染色体信息,每条染色体的偏移信息和长度信息。我们原本可以去掉染色体名,将所有的序列保存到一个文件中,但是这会导致文件过大,不利于后续的读取操作。因此,李恒采用了一种计算方式,使得只用四分之一的体质保存原来的信息。
