C语言标准库并没有字典(map)和集合(set)这种数据结构,因此如果想需要在C语言使用这种数据结构,要么自己根据不同数据类型都写一种函数,或者就是用别人写好的数据结构来用。
Khash.h提供了一种基于开放寻址法的泛型的哈希表, 这里的开放寻址法是一种解决哈希冲突的方法,当哈希函数时计算的位置已经有元素的时候,它会基于当前位置往后探测(probe), 找到一处没有元素的位置。当然还有一种方法,就是拉链法,也就是在冲突的地方,创建一个链表,里面存放具有相同哈希地址的不同元素。
哈希函数
khash.h根据不同的初始化函数会替换成不同的哈希函数,一共有是那种int,int64和str
#define kh_int_hash_func(key) (khint32_t)(key)
#define kh_int64_hash_func(key) (khint32_t)((key)>>33^(key)^(key)<<11)
#define kh_str_hash_func(key) __ac_X31_hash_string(key)
int就是将原值转换成khint32_t,int64用到了位运算,通过右移,按位异或和左移操作,最后转换成khint32_t。这两个哈希函数都非常简单,降低了哈希函数计算的时间。
稍微复杂的就是字符串的哈希函数, 它的计算方式如下
static kh_inline khint_t __ac_X31_hash_string(const char *s)
{
khint_t h = (khint_t)*s;
if (h) for (++s ; *s; ++s) h = (h << 5) - h + (khint_t)*s;
return h;
}
此外还有一个在2011-09-16 (0.2.6)增加的哈希函数kh_int_hash_func2, 能够比较好的处理一些不怎么随机的数据,它的计算过程就非常的复杂了,默认不启用,。
static kh_inline khint_t __ac_Wang_hash(khint_t key)
{
key += ~(key << 15);
key ^= (key >> 10);
key += (key << 3);
key ^= (key >> 6);
key += ~(key << 11);
key ^= (key >> 16);
return key;
}
#define kh_int_hash_func2(key) __ac_Wang_hash((khint_t)key)
数据结构
数据结构通常和算法都是搭配使用,因此理解这个数据结构的设计,就能理解后续的代码逻辑。
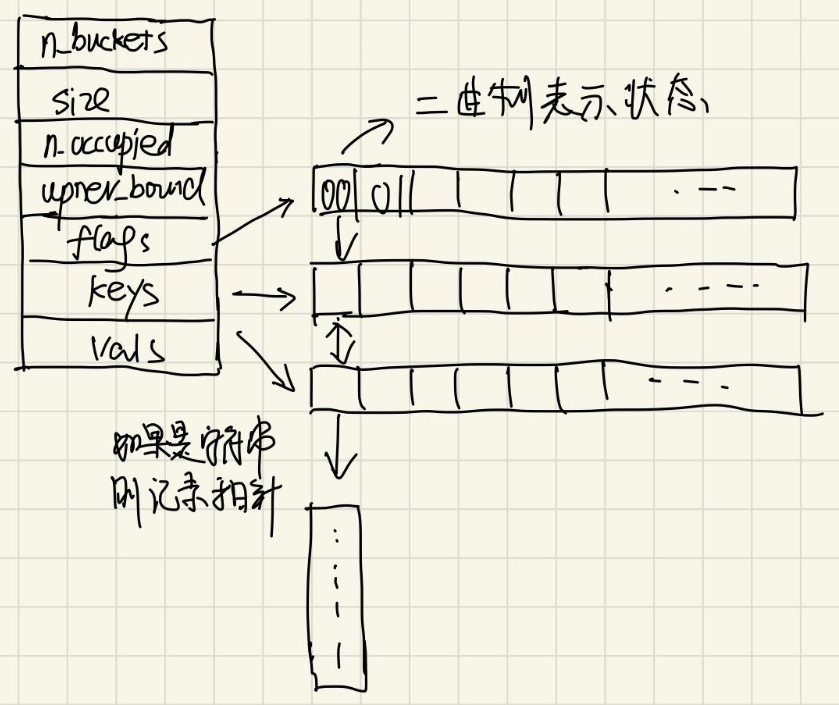
khash.h的定义的kh_##name##_t数据结构一共有7个部分
- n_buckets: 记录桶的数目,也就是哈希表的空间
- size: 当前记录元素
- n_occupied: 当前占据的多少元素
- upper_bound: 上限大小
- flags: 记录当前位置是否有数据
- keys: 指向key的指针
- vals: 指向value的指针
#define __KHASH_TYPE(name, khkey_t, khval_t) \
typedef struct kh_##name##_s { \
khint_t n_buckets, size, n_occupied, upper_bound; \
khint32_t *flags; \
khkey_t *keys; \
khval_t *vals; \
} kh_##name##_t;
关于桶的大小n_buckets:作者以2的n次方大小,保证有足够的空间,降低哈希碰撞。
关于size和n_occupied: 之所以有两个变量来记录哈希表中的元素,是为了降低删除运算。我们不需要在每一次删除运算时,都进行内存的释放和调整,而只要将对应的位置标记为删除状态即可,也就是减少size,而不减少n_occupied.
关于上限upper_bound: 当桶剩下的空间不够时,那么出现哈希碰撞的概率就会变大,因此就需要对哈希表进行调整,计算公式如下。
tatic const double __ac_HASH_UPPER = 0.77;
h->upper_bound = (khint_t)(h->n_buckets * __ac_HASH_UPPER + 0.5);
剩下的flags,keys和vals都是指针,用于指向实际地址,是实际记录数据类型的数据结构。
new_flags = (khint32_t*)kmalloc(__ac_fsize(new_n_buckets) * sizeof(khint32_t));
memset(new_flags, 0xaa, __ac_fsize(new_n_buckets) * sizeof(khint32_t));
khkey_t *new_keys = (khkey_t*)krealloc((void *)h->keys, new_n_buckets * sizeof(khkey_t));
khval_t *new_vals = (khval_t*)krealloc((void *)h->vals, new_n_buckets * sizeof(khval_t));

具体的赋值和删除操作,在后续介绍。
初始化、清空和删除
khash使用kcalloc(等同于calloc)申请一个大小为1的kh_##name##_t, 所有元素默认值都是0.
SCOPE kh_##name##_t *kh_init_##name(void) { \
return (kh_##name##_t*)kcalloc(1, sizeof(kh_##name##_t)); \
}
SCOPE第一层替换代码是static kh_inline klib_unused, 第二层替换就是static inline __attribute__ ((__unused__)). static inline用于提高函数的执行效率,但是此类函数如果没有被使用,编译器会有警告,但是定义了__attribute__ ((__unused__))就可以避免这种警告。
因此,SCOPE是一种提高代码执行效率的函数修饰符。
和初始化相对的操作,一种是清空表里的元素,也就是将size和n_occupied都设置为0,把所有的flags都设置为0xaa也就是为空
SCOPE void kh_clear_##name(kh_##name##_t *h) \
{ \
if (h && h->flags) { \
memset(h->flags, 0xaa, __ac_fsize(h->n_buckets) * sizeof(khint32_t)); \
h->size = h->n_occupied = 0; \
} \
}
另一种是直接释放所有内存。但它不会释放你在堆(heap)中申请的动态内存),也就是你需要自己手动释放你为字符串类型的key和value申请的内存。
SCOPE void kh_destroy_##name(kh_##name##_t *h) \
{ \
if (h) { \
kfree((void *)h->keys); kfree(h->flags); \
kfree((void *)h->vals); \
kfree(h); \
} \
} \
状态(flag)设置和查询
在kh_##name##_t数据结构中,flags用于记录不同位置的状态。为了节约空间,flags用的1/16的桶大小来记录信息。
这是因为flags是一个指向khint32_t元素的指针,khint32_t表示的是32位无符号整型,如果使用2个二进制位表示状态,那么一个32位无符号整型就能记录16个元素。
#define __ac_fsize(m) ((m) < 16? 1 : (m)>>4)
new_flags = (khint32_t*)kmalloc(__ac_fsize(new_n_buckets) * sizeof(khint32_t));
memset(new_flags, 0xaa, __ac_fsize(new_n_buckets) * sizeof(khint32_t));
那么这里有一个问题,为啥不用一个二进制位来表示每个位置的状态呢?这是因为记录的状态有4种,分别是
-
empty(10): 空,没有存放key
-
delete(01), 虽然有key,但是标记为删除
-
either(11): 要么是空,要么是删除了,总之可以放key
-
occupied(00): 已经占用了元素
所以,必须要用2个二进制位。使用memset设置的0xaa对应二进制的0b10101010, 表示默认状态是empty.
下面这四行用于设置第i位的状态
#define __ac_set_isdel_false(flag, i) (flag[i>>4]&=~(1ul<<((i&0xfU)<<1)))
#define __ac_set_isempty_false(flag, i) (flag[i>>4]&=~(2ul<<((i&0xfU)<<1)))
#define __ac_set_isboth_false(flag, i) (flag[i>>4]&=~(3ul<<((i&0xfU)<<1)))
#define __ac_set_isdel_true(flag, i) (flag[i>>4]|=1ul<<((i&0xfU)<<1))
在设置第i位状态时,也就是设置i右移四位(也就是除以16)的状态,接着用((i&0xfU)<<1))计算出状态左移步数,例如i=17时,左移2位,i=16时, 左移0位。
如果我们设置的是is(del|empty|both)_false, 也就是需要反向设置,那么还需要对状态按位取反。接着和原来的情况按位与操作。
相对于设置状态,提取状态就变得容易些,只需要提取对应位置的状态,然后左移,然后和状态进行按位与运算即可。
#define __ac_isempty(flag, i) ((flag[i>>4]>>((i&0xfU)<<1))&2)
#define __ac_isdel(flag, i) ((flag[i>>4]>>((i&0xfU)<<1))&1)
#define __ac_iseither(flag, i) ((flag[i>>4]>>((i&0xfU)<<1))&3)
ul: unsigned long, 无符号长整型0xfU: f就是10进制的16, U表示unsigned(无符号),等价于2进制的0b1111U
如果是我设计flag的话,我估计会申请一个和key大小一样内容空间,直接用1/2/3的数字来表示,而不会用到位运算了。
key、value相关操作
当我们的键值对中的key=1001, 我们是不可能申请一个1001大小的数组用于存放key。否则,当我们要存放key=1和key=10001,我们就会浪费大量的内存空间。为了根据key查询对应的value,我们也需要申请同样大小的空间,那么就会浪费大量的空间。
为了节约空间,我们只会有和桶等大小的内存空间,来放key和value
khkey_t *new_keys = (khkey_t*)krealloc((void *)h->keys, new_n_buckets * sizeof(khkey_t));
khval_t *new_vals = (khval_t*)krealloc((void *)h->vals, new_n_buckets * sizeof(khval_t));
那么面对一个范围比较大的key,我们如何将key映射到有限大小的桶中呢? 在讲解实际代码之前,我们先以几个具体的例子讲解背后的逻辑。
假如目前的桶大小为16(n_buckets=16), 但是我们的key是10001,我们是无法直接将key放入桶中。由于32位整型的哈希函数就是返回原值,那么 k=10001,显然依旧无法放入桶中。这个时候,我们就需要引入一个取模的概念,所谓的取模,就是将我们的key和桶的大小相除,得到剩下的余数,也就是 10001 % 16 = 1,也就是在index=1的位置存放key。取模保证了我们再大的数字都能落在一个固定范围内,例如 1223423423423 % 16 = 15。为了提高取模运算,我们可以用一个等价的位运算10001 & 15来加速,15的二进制表示为0b01111,也就是无论一个数字有多大,最终只有最后的四位可以不为0.
取模操作会有一个问题,就是不同的数字会有相同的余数,例如17求余之后也是1。那么此时应该处理呢?解决方法有很多种,khash.h采用的方法就是,在冲突的地方往后找空位。也就是,我们可以在2的位置插入17。
在查询操作的时候,也不能直接返回模运算得到的位置,而是将位置的key和我们查询的key进行比较,如果相同才能返回。
除了插入和查询外,我们还有一个删除操作。为了提高效率,我们执行删除操作时,需要将对应位置标记为删除态即可,等到空间存在过多的删除位置时,我们才考虑做一次空间调整。
khash.h中kh_put_##name,kh_get_##name这两个函数都需要根据key计算index分别对应
- 根据给定的key获取桶的位置,并在keys对应的位置上加入计算后的key
- 根据给定的key查询桶的位置
有了桶具体位置之后,kh_key,kh_val,kh_del_##name就可以对key和value进行修改或删除。
接下来的部分就是具体的代码讲解
put
kh_put_##name,对应khash.h的307-348行,分两个部分
第一部分,判断当前占用元素(n_occupied)是否超出了可容纳元素的上限(upper_bound) ,也分为两种情况,一种是真的满了,另一种是大部分都是删除状态), 如果是的话,就需要调整哈希表的大小(在下一部分介绍),如果调整失败,会直接返回当前桶的最后一个位置。否则会进入第二部分
if (h->n_occupied >= h->upper_bound) { /* update the hash table */ \
if (h->n_buckets > (h->size<<1)) { \
if (kh_resize_##name(h, h->n_buckets - 1) < 0) { /* clear "deleted" elements */ \
*ret = -1; return h->n_buckets; \
} \
} else if (kh_resize_##name(h, h->n_buckets + 1) < 0) { /* expand the hash table */ \
*ret = -1; return h->n_buckets; \
}
} /* TODO: to implement automatically shrinking; resize() already support shrinking */ \
注意,这里的ret, 一共有-1, 0, 1, 2 这四种状态,分别表示操作失败,key在表中出现,桶为空,桶是删除状态
第二部分,根据key计算index,找到待插入桶的位置,代码一共有7个变量
khint_t x;
khint_t k, i, site, last, mask = h->n_buckets - 1, step = 0; \
x = site = h->n_buckets; k = __hash_func(key); i = k & mask; \
- x: 最终返回的位置
- k: 根据key计算哈希值
- i: 哈希值基于mask的求模结果
- site: 上一个标记删除的位置
- last: 第一次算出的i的位置
- mask: 用于对i进行求模
- step: 哈希冲突后的往后移动的步数
查找可用位置的代码如下
if (__ac_isempty(h->flags, i)) x = i; /* for speed up */ \
else {\
last = i; \
while (!__ac_isempty(h->flags, i) && (__ac_isdel(h->flags, i) || !__hash_equal(h->keys[i], key))) {\
if (__ac_isdel(h->flags, i)) site = i; \
i = (i + (++step)) & mask; \
if (i == last) { x = site; break; } \
} \
if (x == h->n_buckets) {\
if (__ac_isempty(h->flags, i) && site != h->n_buckets) x = site; \
else x = i; \
} \
} \
即便最简单的情况是__ac_isempty(h->flags, i),也就是待插入的位置为空,也要分为三种情况考虑,
- 没有碰撞:
x = i,site=h->n_buckets - 出现碰撞,往后探测过程中没有删除位置:
x=site=h->n_buckets - 出现碰撞,往后探测过程中有删除位置:
x=h->buckets,site=i
如果不为空,那么考虑key重复的情况,也就是待插入的位置的哈希值和当前key的哈希值相同,也就是!__ac_isdel(h->flags, i) && __hash_equal(h->keys[i], key)), 也分为两种请
- 没有碰撞,
x=site=h->n_buckets - 出现碰撞,往后探测过程中没有删除位置:
x=site=h->n_buckets - 出现碰撞,往后探测过程中有删除位置:
x=h->buckets,site=i
最麻烦的情况是,找了一圈,回到最初的位置i=last, 那么此时x=site=i
不存在所有元素都是delete,或者所有元素都是occupied的情况,因为一旦超过一个容纳上线,哈希表会自动扩容。
最后,如果x!=h->n_buckets, 我们是找了一圈,我们直接使用上一个标记为删除的位置,否则考虑两种情况
- 如果找到的位置为空,且中间有删除的位点的话,我们优先用删除的位置
- 换言之,找到的位置不为空,或者中间没有删除位置,那就用有相同哈希的位置或者中间的空位
if (x == h->n_buckets) { \
if (__ac_isempty(h->flags, i) && site != h->n_buckets) x = site; \
else x = i; \
} \
最后,分三种情况考虑
- 如果是x的位置为空,标记状态,并增加size和n_occupied
- 如果是x的位置标记为删除,标记状态,只增加size
- 否则就说明是重复元素,不做任何操作,返回状态是0
if (__ac_isempty(h->flags, x)) { /* not present at all */ \
h->keys[x] = key; \
__ac_set_isboth_false(h->flags, x); \
++h->size; ++h->n_occupied; \
*ret = 1; \
} else if (__ac_isdel(h->flags, x)) { /* deleted */ \
h->keys[x] = key; \
__ac_set_isboth_false(h->flags, x); \
++h->size; \
*ret = 2; \
} else *ret = 0; /* Don't touch h->keys[x] if present and not deleted */ \
get
kh_get_##name的含义是 查询,根据给定的key,在哈希表中查找是否有元素,并返回哈希表对应的位置。由于存在哈希冲突的可能,因此查询过程中还需要比较查询的key和哈希表记录的key值是否相同。
SCOPE khint_t kh_get_##name(const kh_##name##_t * h, khkey_t key) \
{ \
if (h->n_buckets) { \
khint_t k, i, last, mask, step = 0; \
mask = h->n_buckets - 1; \
k = __hash_func(key); i = k & mask; \
last = i; \
while (!__ac_isempty(h->flags, i) && (__ac_isdel(h->flags, i) || !__hash_equal(h->keys[i], key))) { \
i = (i + (++step)) & mask; \
if (i == last) return h->n_buckets; \
} \
return __ac_iseither(h->flags, i)? h->n_buckets : i; \
} else return 0; \
}
一共定义了5个变量
- k: k是哈希函数计算结果
- i: 存放key和value值的索引(index)
- last: 起始的index
- mask: 用于取模,将key限制在桶大小以内
- step: 哈希碰撞后,往后移动
如果理解了插入的逻辑,那么查询的逻辑其实更简单。查询的目标是找到被占用的位置,且该位置上的key的哈希值和我们查询的key的哈希值相同。
delete
kh_del_##name操作最为简单,就是根据你提供的index(注意他是需要你提供key计算好的index),来标记桶对应位置为删除状态,但不会实际释放对应位置上key和value的内容。删除的时候,我们得保证索引位置不是桶的最后一个位置,也不是空状态或者删除状态。
SCOPE void kh_del_##name(kh_##name##_t * h, khint_t x) \
{ \
if (x != h->n_buckets && !__ac_iseither(h->flags, x)) { \
__ac_set_isdel_true(h->flags, x); \
--h->size; \
} \
}
调整空间
显然初始化内存大小是无法记录元素的,以及如果新增元素超过当前哈希表所能容纳的大小,或者哈希表中大部分的元素都被删除,不需要那么多空间,我们都需要对哈希表的空间进行调整。因此在khash.h有62行代码,即244-306,是负责哈希表的大小调整。
khash.h代码中只有kh_put_##name在h->n_occupied >= h->upper_bound时会调用kh_resize_##name,而且是先考虑h->n_buckets > (h->size<<1), 如果桶大小比实际存放元素数的2倍还大,说明是标记删除元素太多了,那么需要清空哈希表,否则是真的不够了。前者传给kh_resize_##name的new_n_buckets = h->n_buckets - 1, 后者new_n_buckets = h->n_buckets + 1
n_buckets会先经过kroundup32函数计算出新哈希表的大小(new_n_buckets),kroundup32涉及到一系列的位运算
#define kroundup32(x) (--(x), (x)|=(x)>>1, (x)|=(x)>>2, (x)|=(x)>>4, (x)|=(x)>>8, (x)|=(x)>>16, ++(x))
它的效果是得到比当前桶的大小大且距离最近的2^n,例如桶的数目是55,那么最近的就是64。如果桶的数目是297, 那么最近的就是512,如果是64,那么就是63。 如果是我写那就只能写出下面这种代码
int roundup32(int x) {
int tmp = x;
int y = 1;
while (tmp) {
tmp >>= 1;
y <<= 1;
}
return x==(y>>1) ? y>>1 : y;
}
接着,它还保证桶的数目最少是4,if (new_n_buckets < 4) new_n_buckets = 4;
我们先考虑申请的空间的可容纳上限比已有元素多的情况
if (h->size >= (khint_t)(new_n_buckets * __ac_HASH_UPPER + 0.5)) j = 0;
khash.h会先计算new_flags的数目,并初始化为0xaa. 如果当前的桶的大小低于新的桶的大小,那么就用krealloc重新申请内存,并将数据拷贝到新的内存地址中。
new_flags = (khint32_t*)kmalloc(__ac_fsize(new_n_buckets) * sizeof(khint32_t)); \
if (!new_flags) return -1; \
memset(new_flags, 0xaa, __ac_fsize(new_n_buckets) * sizeof(khint32_t)); \
if (h->n_buckets < new_n_buckets) { /* expand */ \
khkey_t* new_keys = (khkey_t*)krealloc((void*)h->keys, new_n_buckets * sizeof(khkey_t)); \
if (!new_keys) { kfree(new_flags); return -1; } \
h->keys = new_keys; \
if (kh_is_map) {
\
khval_t* new_vals = (khval_t*)krealloc((void*)h->vals, new_n_buckets * sizeof(khval_t)); \
if (!new_vals) { kfree(new_flags); return -1; } \
h->vals = new_vals; \
} \
} /* otherwise shrink */
上面的代码相对简单,最复杂的268-294行重新计算hash的过程。重新计算哈希的本质本质就是缩小哈希表。
因为桶的大小是按照4,8,16,32,64,128,256,512,1024这种方式增加,所以只要是增加空间,当前的元素数目是不可能高于新的桶大小的可容纳范围的上限的。只有在h->n_buckets <= (h->size<<1)的情况下,也就是当前空间一般都是删除的元素的情况下,才会出现当前元素数目大于桶的可容纳上限的情况。
此时新的空间大小变为原来的一半,那么里面的元素就需要移动位置。搬运的时候,很有可能出现哈希碰撞。
搬运过程是一个嵌套循环,外层循环遍历旧哈希表的每个桶,如果发现它该位置上有元素,就记录它的key和value,然后我们算下它在新哈希表位置(如果找到不为空的,就往后移动),并将新位置标记为不为空。同时检查新哈希表位置对应的旧哈希表位置上是否有元素,如果有,就把该元素和待插入元素进行交换,我们的下一个任务就是为这个元素查找位置,否则就可以退出了。
for (j = 0; j != h->n_buckets; ++j) {
\
if (__ac_iseither(h->flags, j) == 0) {
\
khkey_t key = h->keys[j]; \
khval_t val; \
khint_t new_mask; \
new_mask = new_n_buckets - 1; \
if (kh_is_map) val = h->vals[j]; \
__ac_set_isdel_true(h->flags, j); \
while (1) { /* kick-out process; sort of like in Cuckoo hashing */ \
khint_t k, i, step = 0; \
k = __hash_func(key); \
i = k & new_mask; \
while (!__ac_isempty(new_flags, i)) i = (i + (++step)) & new_mask; \
__ac_set_isempty_false(new_flags, i); \
if (i < h->n_buckets && __ac_iseither(h->flags, i) == 0) { /* kick out the existing element */ \
{ khkey_t tmp = h->keys[i]; h->keys[i] = key; key = tmp; } \
if (kh_is_map) { khval_t tmp = h->vals[i]; h->vals[i] = val; val = tmp; } \
__ac_set_isdel_true(h->flags, i); /* mark it as deleted in the old hash table */ \
}
else { /* write the element and jump out of the loop */ \
h->keys[i] = key; \
if (kh_is_map) h->vals[i] = val; \
break; \
} \
} \
} \
}
接下来的工作就是用krealloc重新调整内存大小, 重新计算其他元信息.
if (h->n_buckets > new_n_buckets) { /* shrink the hash table */ \
h->keys = (khkey_t*)krealloc((void*)h->keys, new_n_buckets * sizeof(khkey_t)); \
if (kh_is_map) h->vals = (khval_t*)krealloc((void*)h->vals, new_n_buckets * sizeof(khval_t)); \
} \
kfree(h->flags); /* free the working space */ \
h->flags = new_flags; \
h->n_buckets = new_n_buckets; \
h->n_occupied = h->size; \
h->upper_bound = (khint_t)(h->n_buckets * __ac_HASH_UPPER + 0.5); \
