这是我2022-02-16在CGM分享的文字稿
从2016年,我开始自学生物信息,那个时候,为了加深自己学习,所以就不间断的在网上分享我的学习笔记。
我有一个自己的博客,xuzhougeng.top。当然,因为自己的名字比较特别,所以你们可以很容易的通过百度,谷歌搜索到我。
当我们在谈论生信的时候,我们实际在谈什么
首先,我们要明确生物信息学到底是什么, 什么是bioinformatics。
不然,我觉得你给一个搞生物的男朋友或者女朋友修电脑,给实验室修打印机,也可以说自己是在搞生物信息嘛。
这里,我用的是维基百科的定义
Bioinformatics (/ˌbaɪ.oʊˌɪnfərˈmætɪks/ (audio speaker iconlisten)) is an interdisciplinary field that develops methods and software tools for understanding biological data, in particular when the data sets are large and complex. As an interdisciplinary field of science, bioinformatics combines biology, chemistry, physics, computer science, information engineering, mathematics and statistics to analyze and interpret the biological data. Bioinformatics has been used for in silico analyses of biological queries using mathematical and statistical techniques
正如定义所说的,生信是一个交叉学科,涉及到各种学科,生物,化学,计算机科学,信息工程,数学,统计学等。
生信会涉及到工具和方法的方法的开发,对生物学数据的分析和解释等。
不难看出,生信是如此的复杂和庞大,因此,即便两个做生信分析的课题组,也可能根本聊不到一块去,甚至互相觉得对方不是在搞生信;
因为我个人局限性,所以,我今天提到的生信学习经验,仅仅是就是其中的高通量数据分析这一小部分而已。

生信入坑前传
先讲讲,我是怎么接触到生物信息学的吧。大概是我大二的时候,我们学院的培养计划,会让我们去找一个指导老师,在我找导师的过程中,就听一个老师说,农学院有一个老师做生物信息学,特别容易发文章。当时,我的梦想是发SCI,我以为SCI就是science的缩写,后来才知道它只是一个数据库而已(Science Citation index)。不过可惜的是,那个老师出国了,所以最后我找的老师,实际上还是传统的湿实验课题组。
到了2016年,我在植生所实习的时候,机缘巧合之下,我的一个师姐给了我2个样本的转录组数据,还有一篇介绍TopHat和Cufflinks的分析流程的参考文献,让我去折腾。
这就是我人生中第一次接触到高通量测序数据,也是我踩得的第一次坑,因此我第一个要分享的经验就是,“永远要搞清楚你的数据”
永远要先搞清楚你的数据
为什么要这样子说呢?
首先,我们要知道高通量测序是有很多类型的,比如说基因组,转录组,表观组,不同测序方法有不同的分析思路。光是基因组,也分为基因组组装,还是重测序分析。
如果你都不知道自己测了什么数据,那你也就不知道你自己可以做哪些分析,也就不知道自己到底应该学什么。
此外,数据质量也非常重要。本来,你是打算测植物的组织的,结果实验准备阶段,材料污染了,测到的90%都是细菌微生物,那你这批数据也就废了。对于有经验的人来说,可能也就是数据不能用而已,大不了重做。但是对于初学者而言,这就非常致命了,因为你可能会怀疑是不是自己的能力问题,是不是软件选错了,是不是代码跑错了。同时,你可能还面临着师兄师姐,导师的方面的压力。他们可能会想,生信不就是跑跑代码嘛,为啥你搞了半天,啥结果都没有啊,那你还是别搞了吧,估计你也不是这块料。于是你的自学之路就这样子断了,多可惜啊!
还有,实验设计也很关键。拿转录组的差异分析来说,大部分的软件是需要你的样本是有重复的,如果你实验设计的时候没有考虑到重复,那你可能就得去找一些冷门的软件了。
我当时拿到的转录组数据就是没有重复的,这就导致我根本无法按照常规思路来处理数据。更重要的是什么呢?这还是我绞尽脑汁,在一年后的某个时刻突然间才想清楚的。
如果你和我一样,也是自学生信,我的建议是,不要直接用你师兄师姐的数据练手,而是找一些已发表文章或者是别人教程数据。先用已经验证的流程来增加的信心,而不是直接开始探索,因为各种奇奇怪怪的问题,对自己的学习能力产生怀疑。
上面说到,我是在一年后的某个时刻,突然想清楚的,于是,这就引出了我第二个要分享的经验,’100小时入门定律‘
100小时入门定律
2014年,有一本畅销书叫做【异类】,讲的是1万小时定律,就是你在某个领域练习1万小时才能成为专家。当然这个并不准确,提出刻意练习的安德斯·艾利克森教授写了一本书,叫做【刻意练习】,讲的是只有正确的练习,才能够从新手变成大师。当然这两本书都有一个关键主题,那就是你得大量的练习,才能掌握一门新技能。
从我的角度讲,自学生信最困难的一个阶段,就是入门阶段。我的自学过程是非常痛苦,因为没有人指导,也不知道自己先去学啥,所以就啥都学,有一段时间就在翻译Biocondutor上的教程。学了很久,都是迷迷糊糊的,感觉跟没学一样。
直到某一次上完生物统计学课之后,在回实验室的路上,我在回忆上课的知识时,突然间脑子有一种通透的感觉,自己学到的知识好像都连在了一起。那个时刻开始,我才觉得,自己终于有能力去处理数据了。而这前前后后,从我第一次接触高通量测序,差不多过去了半年时间了。
因此,如果你要自学生信,那你就得明白,这个事情真的得花上不少的时间。在这里,我有两个不成熟的小建议
- 导师充足的信任,心无旁骛的自学
比如说,我的研一阶段基本上就是在自学,王老师基本上没有怎么管我。因此,即便有些问题卡了我好几天,我都不会泰国焦虑,因为我有足够的的时间去找到原因,并解决他。 - 掌握好实验技能,慢慢学习
比如说,我的一个师兄,张天奇博士,原本是做传统湿实验的,博后阶段,他在MP,NC,DC上发表了多篇植物单细胞的文章,这里面的单细胞数据分析部分都是他自己完成的。在我来王老师课题组之前,他并没有太多Linux和R语言基础,也是花了很多时才掌握的。
假如,你终于入门了生信,这个时候,你可能会有一段时间,自信心爆棚,感觉自己都会,只要花时间,什么分析你都能做。于是,这就引入了我第三个要分享的经验,‘你不应该什么都会’
你不应该什么都会
因为你是自学,所以你应该是课题组第一个会做数据分析的人。一开始,你可能就只需要处理RNA-seq数据,慢慢的,你可能要处理ChIP-seq, ATAC-seq。一开始你是不会的,但是经过一段时间学习,你发现自己也差不多会了。于是你的自信心爆棚,感觉高通量数据数据处理不过如此,只要花点时间,你就什么都会了。
但是,我想说的是,你要小心这个状态。你很有可能会跟天龙八部的鸠摩智一样,好像样样都会,但是深究起来,可能就知道皮毛个皮毛而已。
因此,我建议,你不要什么都学;有些分析如果公司有了成熟分析流程,那就让公司完成上游分析,自己专注于更加重要的生物学意义上。尝试去教会你的是师弟师妹,师兄师姐,让他们自己做一些分析,让实验室有一个生信的传统。
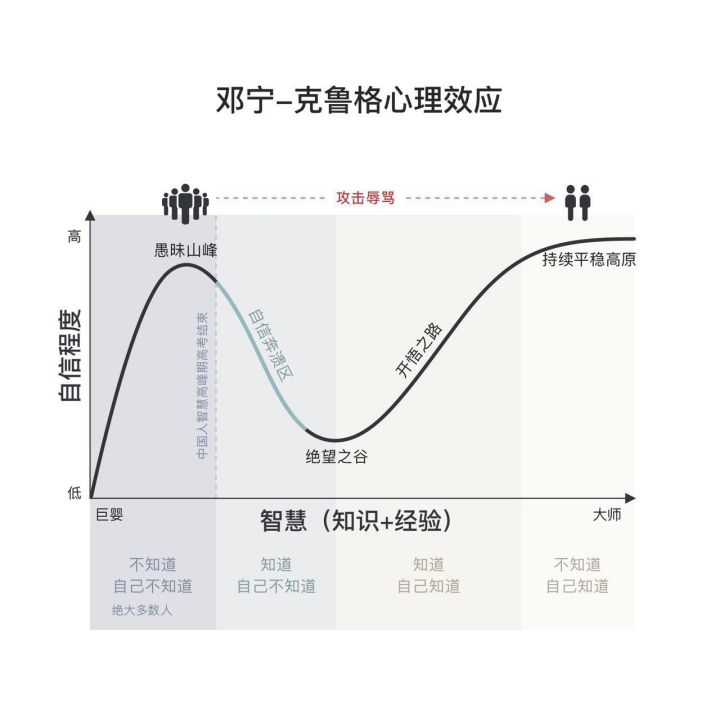
邓宁-克鲁格心理效应
最后,我想用一个心理学效应来结束本次分享。
在我们学习一个技能的时候,我们随着自己技能水平的提高,自信心会不断增加。感觉自己好像什么都知道一样,但是随着你知识的继续增加,你会发现自己其实什么都不会,你就会开始迷茫,会经历了一个自信心崩塌的过程。这个时候,我们还得坚持下去,坦然接受自己的不足,并补足它。最终,你会走到另一个高峰。