首先安装autocoder
conda create --name autocoder python=3.10.11
conda activate autocoder
pip install -U auto-coder
## if you want to use private/open-source models, uncomment this line.
pip install -U vllm
ray start --head
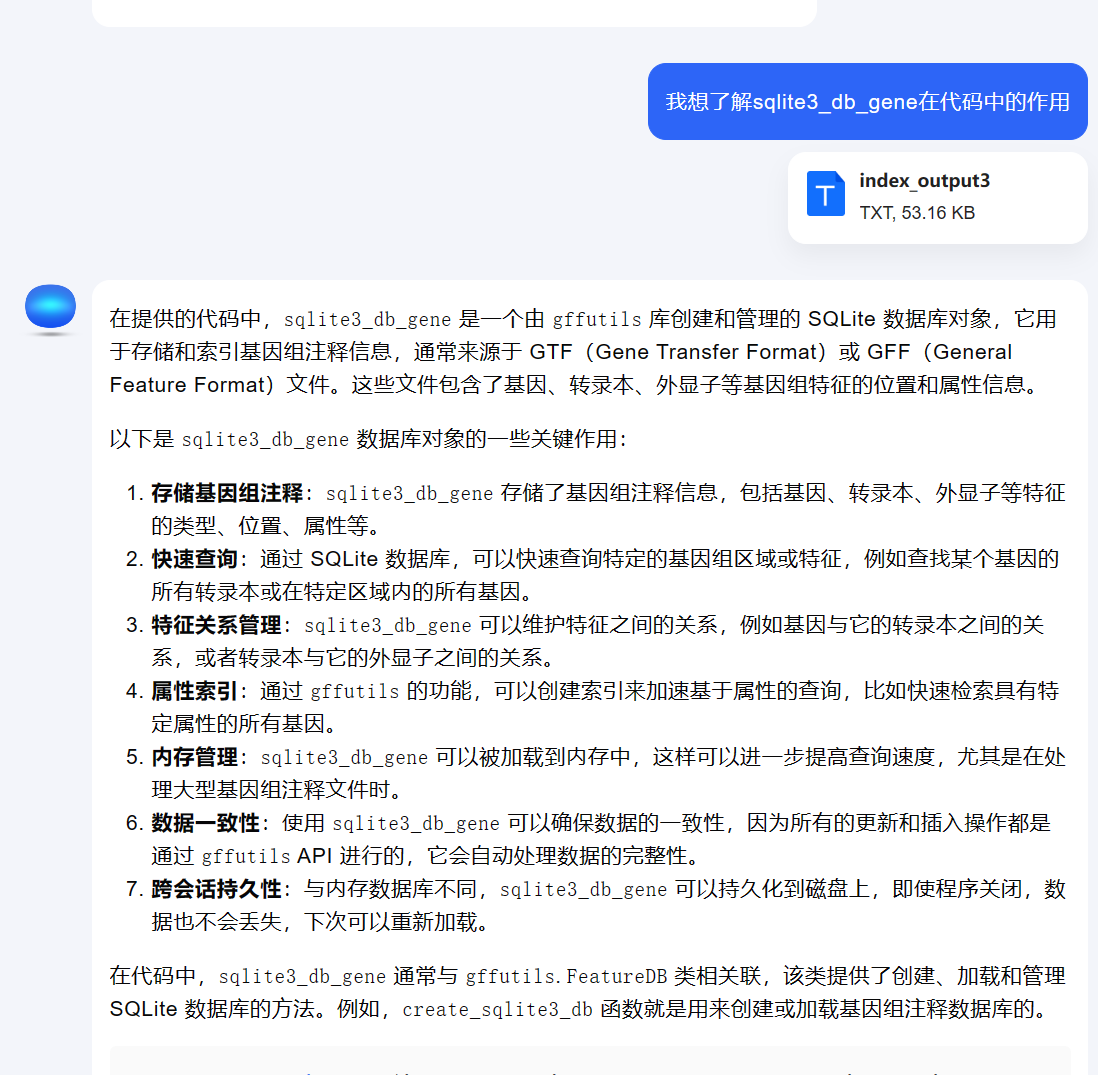
接下里部署moonshoot提供的模型,为啥选择moonshoot,主要是因为我申请了他们家的API,用的顺手了。
byzerllm deploy --pretrained_model_type saas/official_openai \
--infer_params saas.api_key={你的API} saas.model=moonshot-v1-128k saas.base_url=https://api.moonshot.cn/v1 \
--model kimi_chat_128k
然后去下载我们的想要学习的源代码
git clone https://github.com/ablab/rnaquast.git
接着,我们写一个配置文件,叫做read_code.yml,内容如下
source_dir: /home/xzg/project/
target_file: /home/xzg/project/output.txt
model: kimi_chat_128k
model_max_length: 2000
model_max_input_length: 100000
anti_quota_limit: 5
project_type: py
skip_build_index: false
query: >
阅读rnaquast源码,找到sqlite3_db_gene相关的函数
需要修改的相关参数是
- source_dir: rnaquast的所在目录
- target_file: 运行结果的输出文件,
- skip_build_index: 设置为false, 那么在运行前就会建立索引
- query: 填写的就是我们需要让auto-coder处理的问题
接着运行代码
auto-coder --file read_code.yml
运行时,会需要一段时间的索引构建过程,主要目标就是从代码中提取一些关键信息,如函数,类,变量,导入语句,对应的prompt如下。
你的目标是从给定的代码中获取代码里的符号,需要获取的符号类型包括:
1. 函数
2. 类
3. 变量
4. 所有导入语句
如果没有任何符号,返回空字符串就行。
如果有符号,按如下格式返回:
```
{符号类型}: {符号名称}, {符号名称}, ...
```
这一步结束后,会在对应的项目录下生成一个.autocoder的文件夹,保存索引。
索引结束后,会有一个绿屏提示,给出那些是最有可能的文件,让你选择
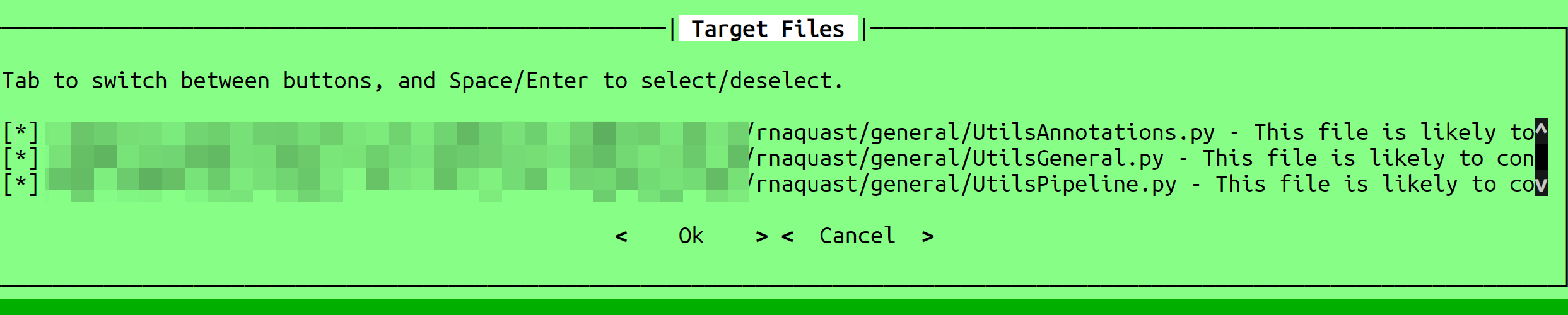
你可以用tab直接跳转到OK,然后回车。
最后你可以查看output.txt,查看相关的源代码,格式如下,用##File来区分不同的文件来源。
##File: /home/xzg/project/plant-sc-rnaseq-atlas-viewer/project/rnaquast/general/UtilsPipeline.py
__author__ = 'lenk'
import argparse
import sys
import subprocess
...
如果想要进一步的对代码解释,可以把output.txt的内容上传给ChatGPT, Claude3,让他们进行解答,比如说我选择了kimi,