Pytorch是目前最火的深度学习框架之一,另一个是TensorFlow。不过我之前一直用到是CPU版本,几个月前买了一台3070Ti的笔记本(是的,我在40系显卡出来的时候,买了30系,这确实一言难尽),同时我也有一台M1芯片Macbook Pro,目前也支持了pytorch的GPU加速,所以我就想着,在这两个电脑上装个Pytorch,浅度学习深度学习。
Apple silicon
首先是M1芯片,这个就特别简单了。先装一个conda,只不过是内置mamba包管理器,添加conda-forge频道,arm64版本。
# 下载
wget https://github.com/conda-forge/miniforge/releases/latest/download/Mambaforge-MacOSX-arm64.sh
# 安装
bash Mambaforge-MacOSX-arm64.sh
然后我们用mamba创建一个环境,用的是开发版的pytorch,所以频道指定pytorch-nightly
mamba create -n pytorch \
jupyterlab jupyterhub pytorch torchvision torchaudio
-c pytorch-nightly
最后,用conda activate pytorch,然后测试是否正确识别到GPU
import torch
torch.has_mps
# True
# 配置device
device = torch.device("mps")
参考资料: https://developer.apple.com/metal/pytorch/
Windows NVIDIA
首先,需要确保你的电脑安装的是NVIDIA的显卡,以及有了相应的CUDA驱动。
CUDA的显卡架构要求: https://docs.nvidia.com/deeplearning/cudnn/support-matrix/index.html
新一代的电脑上基本都自带CUDA驱动。可以通过打开NVIDIA控制面板的系统信息
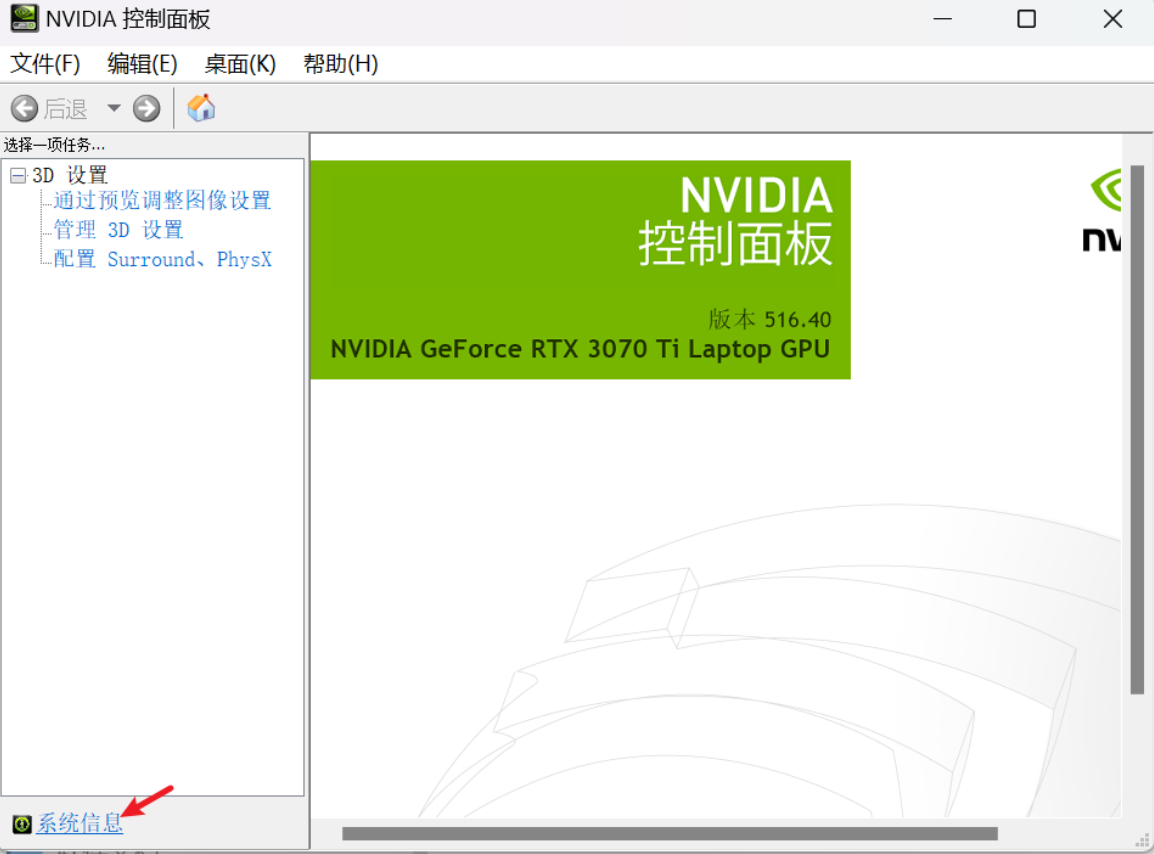
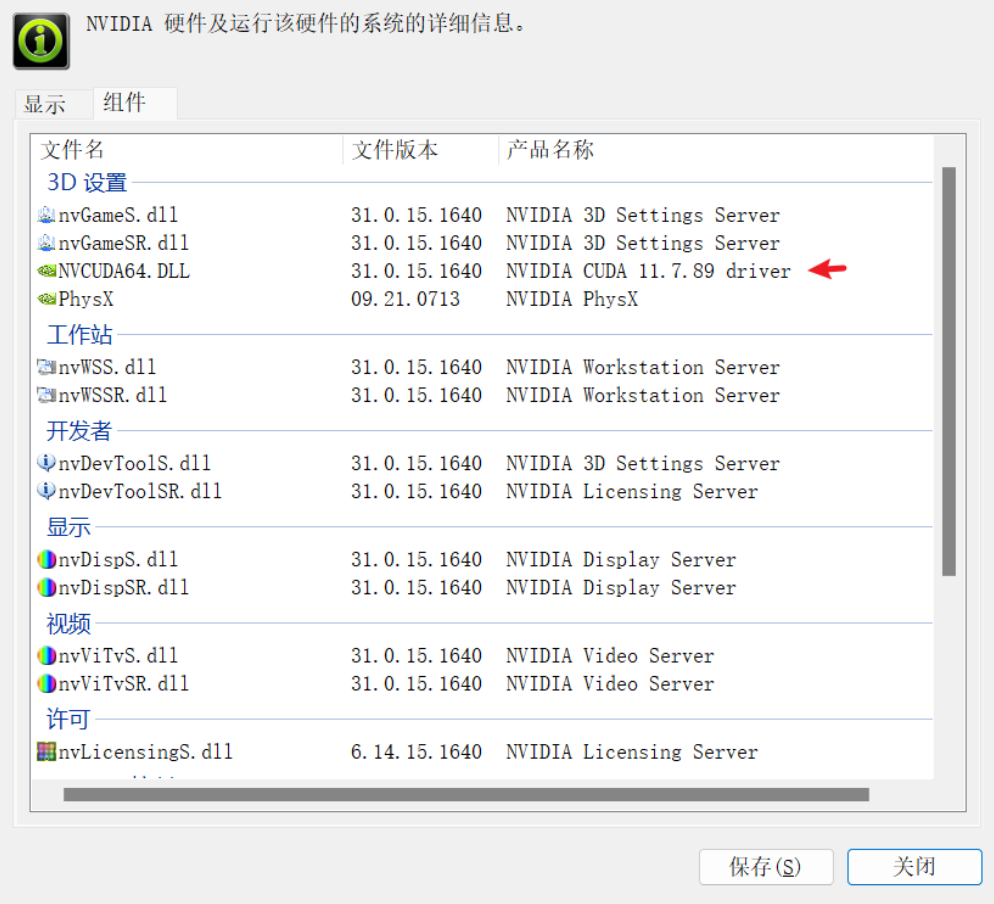
在组件中查看你已经安装的CUDA驱动,例如我的是11.7.89 。
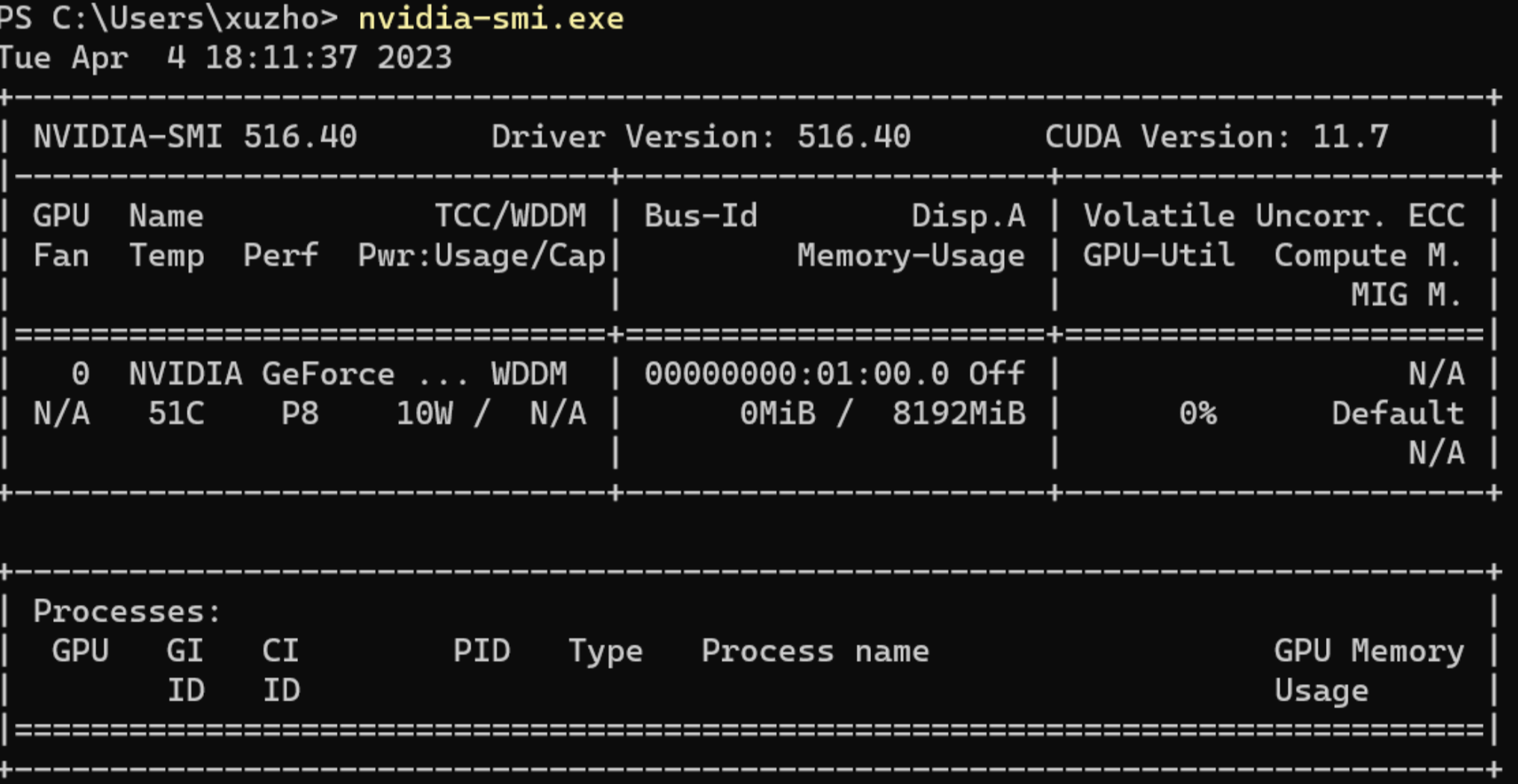
也可以通过命令行的方式查看,
接下来,我们来安装pytorch。同样也是推荐conda的方法,我们先从清华镜像源中下载Miniconda。
选择Windows的安装包
安装完之后,我们就可以通过Anaconda Prompt进入命令行,根据pytorch网站上的推荐进行安装。
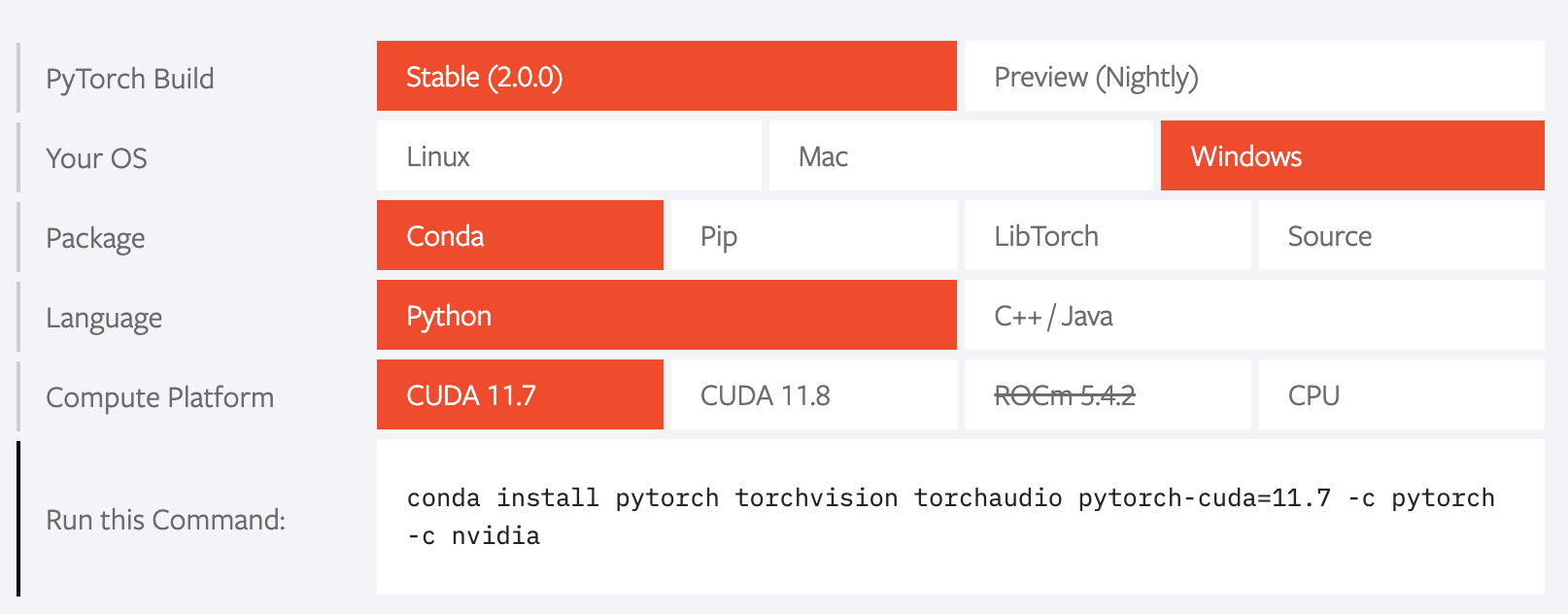
但是有一点不同,为了避免环境冲突,最好是单独创建一个环境,所以代码如下
conda create -n pytorch pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
接着用 conda activate pytorch启动环境,然后在python环境中测试
import torch
torch.has_cuda
# True
几个常见的问题(至少我在写文章想到的问题):
Q: 使用conda和pip安装的区别是什么?
A: conda是pytorch官方推荐的安装方式,因为conda会一并帮你装好pytorch运行所需要的CUDA驱动和相关工具集。这意味着为conda所占用的空间会更多一些。
Q: 既然conda那么强,是不是让conda帮我在非常老的硬件上安装最新的pytorch吗?
A: 我觉得这个跟装游戏类似,你虽然能装上游戏,但是不满足游戏的最低配置需求,照样跑不动。放在conda上,conda虽然能给你配置好cuda驱动,但是cuda驱动本身对系统的显卡驱动有要求。如果你的显卡驱动不满足,那么就算装好了,也会报错。RuntimeError: The NVIDIA driver on your system is too old
Q: 电脑上必须要安装CUDA驱动和安装CUDA toolkit吗?
A: 其实我个人不是很确定如何回答,如下是我目前的一些见解。如果你用的conda,那么他会帮你解决一些依赖问题。如果你是用pip,那么就需要你自己动手配置。其中,CUDA驱动是必须要安装的,因为CUDA驱动负责将GPU硬件与计算机操作系统相连接,不装驱动,操作系统就不识别CUDA核心,相当你没装NVIDIA显卡。而CUDA toolkit是方便我们调用CUDA核心的各种开发工具集合,你装CUDA toolkit的同时会配套安装CUDA驱动。除非你要做底层开发,或者你需要从源码编译一个pytorch,否则我们大可不装CUDA toolkit。
Q: 如果我电脑上的CUDA驱动版本比较旧怎么办?或者说我CUDA的驱动版本是11.7,但是我安装了cuda=11.8的pytorch,或者版本不一样的pytorch会怎么样?
A: 我们在安装cuda=11.7的pytorch,本质上安装的是在CUDA Toolkit版本为11.7环境下编译好的pytorch版本。当cuda版本之间的差异不是特别的大,或者说不是破坏性的升级的情况下,那么理论上也是能运行的。
手写数据性能测试
下面用的是GPT3.5给我提供一段手写字识别(MNIST)案例代码,用来测试不同的平台的速度。
import torch
import torchvision
import torchvision.transforms as transforms
# 转换数据格式并且加载数据
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=2)
testset = torchvision.datasets.MNIST(root='./data', train=False,
download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64,
shuffle=False, num_workers=2)
# 定义网络模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 6, 5)
self.pool = torch.nn.MaxPool2d(2, 2)
self.conv2 = torch.nn.Conv2d(6, 16, 5)
self.fc1 = torch.nn.Linear(16 * 4 * 4, 120)
self.fc2 = torch.nn.Linear(120, 84)
self.fc3 = torch.nn.Linear(84, 10)
def forward(self, x):
x = self.pool(torch.nn.functional.relu(self.conv1(x)))
x = self.pool(torch.nn.functional.relu(self.conv2(x)))
x = x.view(-1, 16 * 4 * 4)
x = torch.nn.functional.relu(self.fc1(x))
x = torch.nn.functional.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
# 这里的代码比较随意,就是用哪个平台运行哪个
# CPU
device = torch.device("cpu")
# CUDA
device = torch.device("cuda:0")
# MPS
device = torch.device("mps")
net.to(device)
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 训练网络
import time
start_time = time.time() # 记录开始时间
for epoch in range(10): # 进行10次迭代训练
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
end_time = time.time() # 记录结束时间
training_time = end_time - start_time # 计算训练时间
print('Training took %.2f seconds.' % training_time)
print('Finished Training')
# 测试网络
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
))
最后统计下来的结果为
Windows平台
- 3070Ti Training took 45.02 seconds.
- i9 12900H Training took CPU 75.65
Mac平台
- M1 Max Training took 50.79 seconds.
- M1 MAX CPU Training took 109.61 seconds.
总体上来说,GPU加速很明显,无论是mac还是Windows。其次是GPU加速效果对比,M1 max芯片比3070Ti差个10%?。
不过目前测试都是小数据集,等我学一段时间,试试大数据集的效果。
