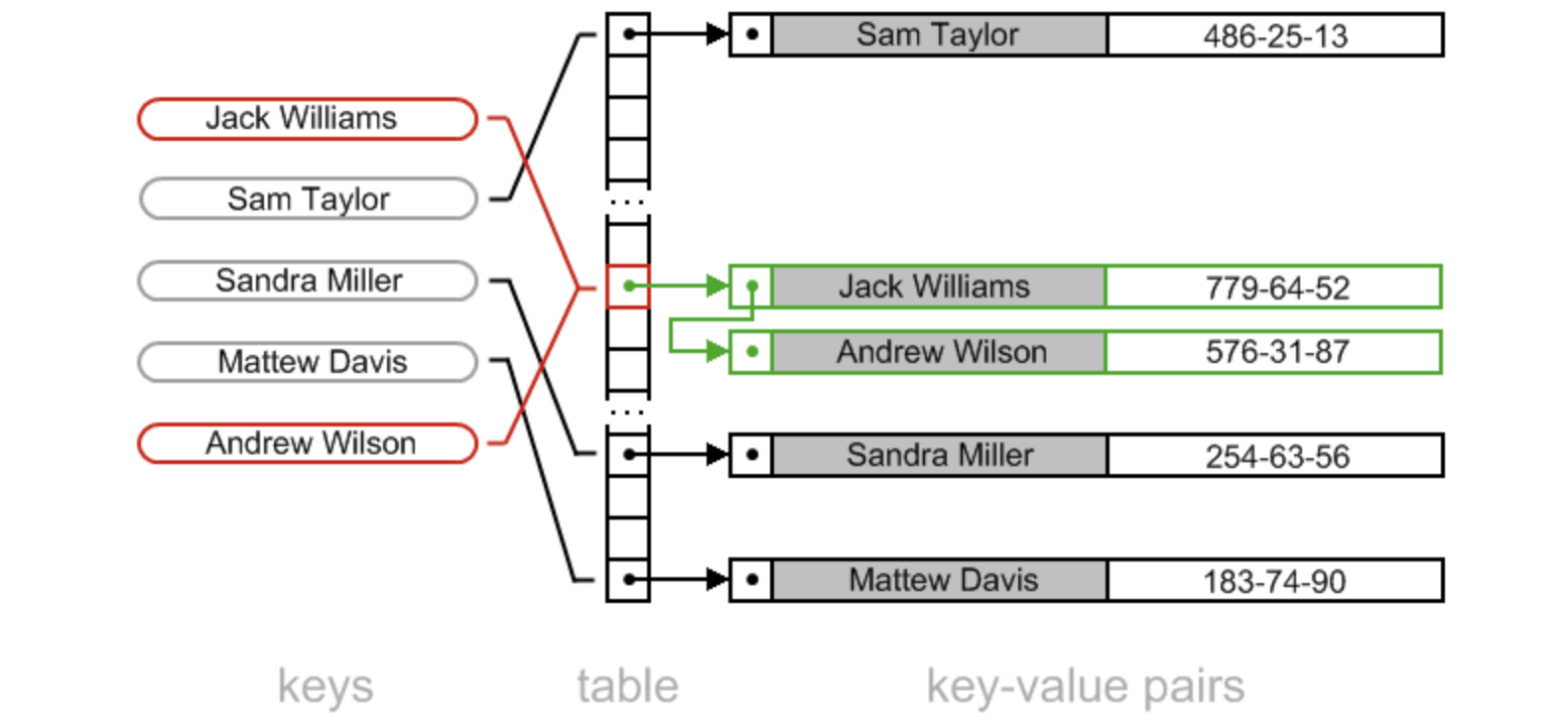
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。 --来源:百度百科
klib提供的khash.h的初始化方法分为两种数据结构,分别是SET和MAP。SET只有键,且键唯一,MAP有键和值,键唯一,而值不唯一。
SET和MAP分别有三种初始化方法,对应键的类型分别为INT,INT64和STR,而哈希算法也分为数值和字符串两类
//SET
#define KHASH_SET_INIT_INT(name) \
KHASH_INIT(name, khint32_t, char, 0, kh_int_hash_func, kh_int_hash_equal)
#define KHASH_SET_INIT_INT64(name) \
KHASH_INIT(name, khint64_t, char, 0, kh_int64_hash_func, kh_int64_hash_equal)
#define KHASH_SET_INIT_STR(name) \
KHASH_INIT(name, kh_cstr_t, char, 0, kh_str_hash_func, kh_str_hash_equal)
//MAP
#define KHASH_MAP_INIT_INT(name, khval_t) \
KHASH_INIT(name, khint32_t, khval_t, 1, kh_int_hash_func, kh_int_hash_equal)
#define KHASH_MAP_INIT_INT64(name, khval_t) \
KHASH_INIT(name, khint64_t, khval_t, 1, kh_int64_hash_func, kh_int64_hash_equal)
#define KHASH_MAP_INIT_STR(name, khval_t) \
KHASH_INIT(name, kh_cstr_t, khval_t, 1, kh_str_hash_func, kh_str_hash_equal)
键值对中的kint32_t和khin64_t和系统有关,用于定义一个很大的取值范围。
#if UINT_MAX == 0xffffffffu
typedef unsigned int khint32_t;
#elif ULONG_MAX == 0xffffffffu
typedef unsigned long khint32_t;
#endif
#if ULONG_MAX == ULLONG_MAX
typedef unsigned long khint64_t;
#else
typedef unsigned long long khint64_t;
#endif
kh_cstr_t的定义是typedef const char *kh_cstr_t;, 是一个不会变的字符串。
这两种类型用于设置KHASH_INIT的参数khkey_t和khval_t, 用于初始化哈希表的结构定义
#define __KHASH_TYPE(name, khkey_t, khval_t) \
typedef struct kh_##name##_s { \
//桶的数目, 哈希表大小, 占用数, 上限
khint_t n_buckets, size, n_occupied, upper_bound; \
khint32_t *flags; \ //记录当前位置是否被使用
khkey_t *keys; \ //键的类型
khval_t *vals; \ //值的类型
} kh_##name##_t;
和哈希表操作有关的函数如下
kh_init(name): 初始化哈希表kh_destroy(name, h); 删除哈希表kh_clear(name, h): 保持哈希表大小不变,清空内容kh_resize(name, h, s): 调整哈希表大小, 运行时它会被自动调用,用于扩容kh_put(name, h, k, r): 将key放在哈希表中,并获取key的位置kh_get(name, h, k): 获取key对应的位置kh_del(name, h, k): 删除哈希表元素kh_exist(h, x): 检查哈希表位置上是否有内容kh_key(h, x): 获取哈希表中x对应的keykh_value(h,x): 获取哈希表中键x的值kh_begin(h): 获取哈希表的起始keykh_end(h): 获取哈希表的最后keykh_size(h): 获取哈希表的大小kh_n_buckets(h): 哈希表中桶的数目kh_foreach(h, kvar, vvar, code): 遍历哈希表,其中键赋值给kvar, 值赋值给vvar,运行code的代码kh_foreach_value(h, vvar, code): 遍历哈希表,其中值赋予给vvar,运行code的代码
为了达到类似于Python的字典操作,例如d = {"abc": "aaa"}和d["abc"],所需要写的代码如下
#include <stdio.h>
#include <string.h>
#include "klib/khash.h"
KHASH_MAP_INIT_STR(dict, char*)
int main(int argc, char *argv[])
{
khiter_t k;
khash_t(dict) *h = kh_init(dict);
int ret;
k = kh_put(dict, h, "abc", &ret);
kh_key(h, k) = strdup("abc");
kh_value(h,k) = strdup("aaa");
k = kh_put(dict, h, "efg", &ret);
kh_key(h, k) = strdup("efg");
kh_value(h,k) = strdup("bbb");
k = kh_get(dict, h, "abc");
printf("%s\n", kh_value(h,k));
for ( k = kh_begin(h); k != kh_end(h) ; k++){
if (kh_exist(h,k)){
free((char*)kh_key(h, k));
free((char*)kh_value(h, k));
}
}
kh_destroy(dict, h);
}
对于字符串,哈希表结构中的keys和vals并不存放实际的值,而是存放字符串的地址,因此如果没有专门内存用于存放键值对对字符串,那么用strdup在内存中获取字符串新的地址。 如果用一个字符串数组存放键值对字符串的地址,代码如下:
#include <stdio.h>
#include <string.h>
#include "klib/khash.h"
KHASH_MAP_INIT_STR(dict, char*)
int main(int argc, char *argv[])
{
khiter_t k;
khash_t(dict) *h = kh_init(dict);
int ret;
char *key[] = {"abc", "efg"};
char *value[] = {"aaa", "bbb"};
// h = {"abc":"efg"}
k = kh_put(dict, h, "abc", &ret);
kh_key(h, k) = key[0];
kh_value(h,k) = value[0];
// h["efg"] = "bbb"
k = kh_put(dict, h, "efg", &ret);
kh_key(h, k) = key[1];
kh_value(h,k) = value[1];
// h["abc"]
k = kh_get(dict, h, "abc");
printf("%s\n", kh_value(h,k));
kh_destroy(dict, h);
}
推荐阅读
