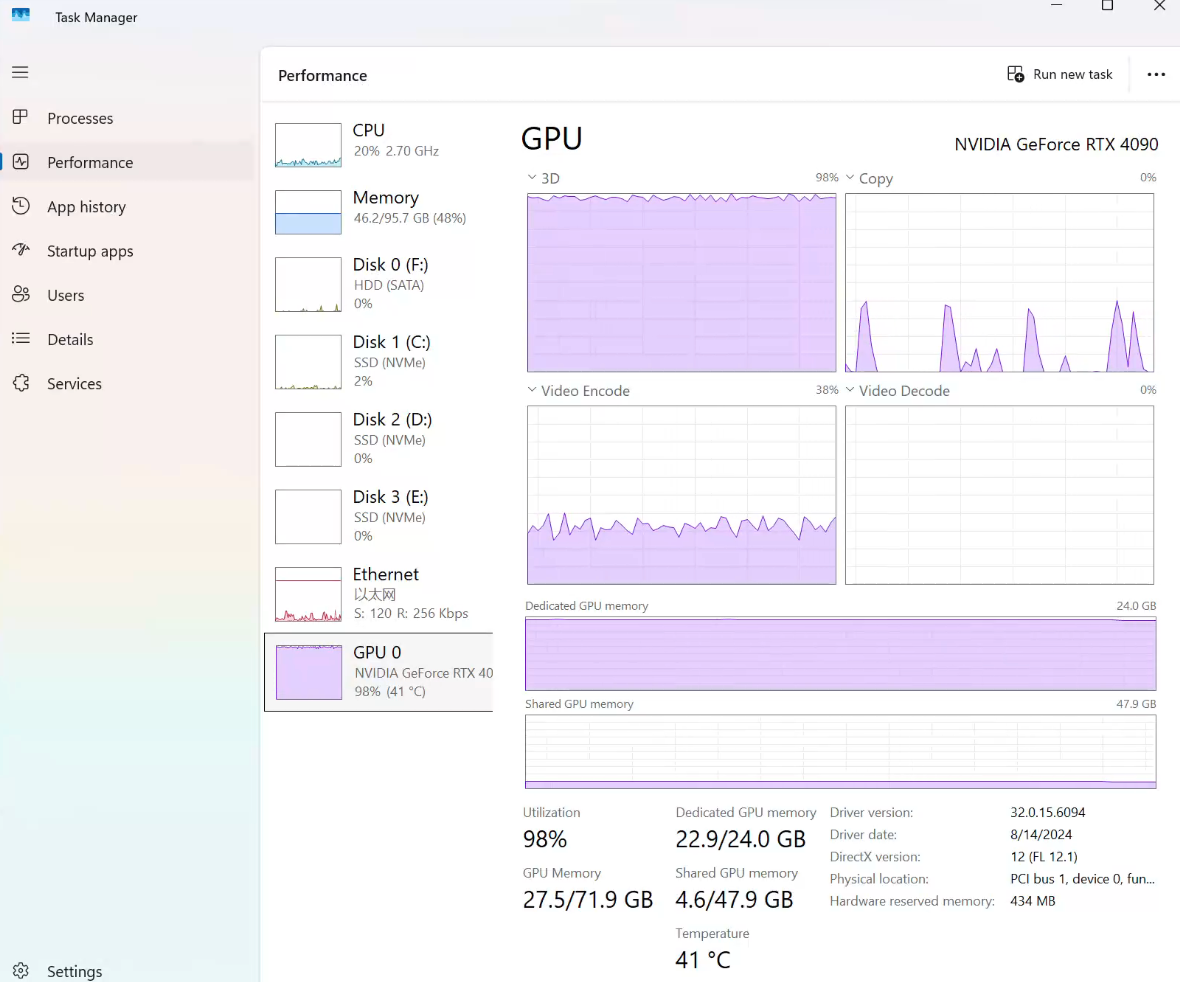
阿里最近推出了一个6B的生图模型,叫做造相(Z-Image),6B参数,模型文件32.9G,经过我测试,刚好可以跑在24G显存的4090 GPU上,以及我的32G内存内存的M1 Pro(实际用了25.6G)
因为用的深度学习框架pytorch可以运行在全平台上,所以如下代码实际上可以在macOS, Linux, Windows上运行。我们配置环境用的是uv,目前python生态里非常优秀的环境管理工具。
使用uv建立一个新的环境
# 如果系统没有安装uv,需要先装uv
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv -p 3.12
source .venv/bin/activate
安装torch,这一步的命令要看平台了,详见 https://pytorch.org/get-started/locally/
# Windows cuda 130的
uv pip install torch torchvision --index-url https://download.pytorch.org/whl/cu130
# macos
uv pip install torch torchvision
安装diffusers
# 安装diffusers和transformers
uv pip install git+https://github.com/huggingface/diffusers
uv pip install transformers
为了提高模型下载速度,我们用的是modelscope,这样子走的就是国内的站点
uv pip install modelscope
modelscope download --model 'Tongyi-MAI/Z-Image-Turbo' --local_dir 'Z-Image-Turbo'
下载的模型位于当前目录下,后续运行的时候需要指定路径,不然会出错。
安装成功后,我们运行如下的代码进行测序。如果是macOS,记得把下面的cuda改成mps,否则会报错。
import torch
from diffusers import ZImagePipeline
# 1. Load the pipeline
# Use bfloat16 for optimal performance on supported GPUs
pipe = ZImagePipeline.from_pretrained(
"./Z-Image-Turbo",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=False,
)
pipe.to("cuda")
# [Optional] Attention Backend
# Diffusers uses SDPA by default. Switch to Flash Attention for better efficiency if supported:
# pipe.transformer.set_attention_backend("flash") # Enable Flash-Attention-2
# pipe.transformer.set_attention_backend("_flash_3") # Enable Flash-Attention-3
# [Optional] Model Compilation
# Compiling the DiT model accelerates inference, but the first run will take longer to compile.
# pipe.transformer.compile()
# [Optional] CPU Offloading
# Enable CPU offloading for memory-constrained devices.
# pipe.enable_model_cpu_offload()
prompt = "Young Chinese woman in red Hanfu, intricate embroidery. Impeccable makeup, red floral forehead pattern. Elaborate high bun, golden phoenix headdress, red flowers, beads. Holds round folding fan with lady, trees, bird. Neon lightning-bolt lamp (⚡️), bright yellow glow, above extended left palm. Soft-lit outdoor night background, silhouetted tiered pagoda (西安大雁塔), blurred colorful distant lights."
import time
start_time = time.time()
# 2. Generate Image
image = pipe(
prompt=prompt,
height=1024,
width=1024,
num_inference_steps=9, # This actually results in 8 DiT forwards
guidance_scale=0.0, # Guidance should be 0 for the Turbo models
generator=torch.Generator("cuda").manual_seed(42),
).images[0]
# 记录结束时间并计算耗时
end_time = time.time()
elapsed_time = end_time - start_time
print(f'消耗时间: {elapsed_time}')
image.save("example.png")
经过我测试,相同的我的M1 Mac需要大概率200秒生成一张图,Windows 的4090需要大概160秒,速度也还行吧。但是,如果是NVIDIA RTX PRO 6000,则需要3秒,一下子差异就有了。因此如果想要体验的话,我建议直接去用在线的站点,毕竟在线用也就只需要10秒而已,还不需要自己配置环境。
PS: 加载模型也需要时间的,模型文件大小是33G,如果不是固态硬盘,可能还需要画个几分钟。
官方提供的在线站点:
- huggingface: https://huggingface.co/spaces/Tongyi-MAI/Z-Image-Turbo
- modelspace: https://www.modelscope.cn/aigc/imageGeneration?tab=advanced&versionId=469191&modelType=Checkpoint&sdVersion=Z_IMAGE_TURBO&modelUrl=modelscope%3A%2F%2FTongyi-MAI%2FZ-Image-Turbo%3Frevision%3Dmaster
下图是我自己测试的效果,用的prompt是:“一个生物信息学家,正在努力的赶项目,前面有三个屏幕(左,右是竖屏),桌边是冰美式,脚下是吃掉的麦当劳”

同样的提示词交给谷歌的生图模式就没有问题,起码冰美式和竖屏都对了。

